728x90

1. 과적합(Overfitting)이란?
- 과적합(overfitting)은 머신러닝 모델이 학습 데이터에 지나치게 최적화되어, 새로운 데이터에 대한 예측 성능이 저하되는 현상을 말합니다.
- 예를 들어, 학생이 시험을 준비할 때, 과거의 시험 문제(족보)만를 모두 외우는 경우를 생각해보세요. 이 학생은 과거 문제에 대해서는 정확한 답을 말할 수 있지만, 새로운 문제 유형에 대해서는 잘 대처하지 못할 것입니다.
- 이처럼 머신러닝 모델도 학습 데이터에만 지나치게 최적화되면, 학습에서 보지 못했던 테스트데이터에 대해서 성능이 떨어지게 됩니다.
- 예를 들어, 얼굴 인식 모델을 학습시키는 경우, 학습 데이터에 포함된 인물들의 얼굴 특징들만 지나치게 학습되어 새로운 인물의 얼굴을 인식하지 못하는 경우가 발생할 수 있습니다.
- 이러한 현상을 과적합이라고 합니다.
2. 과적합이 중요한 이유
- 머신러닝 모델 학습의 목적은 학습 데이터를 잘 학습하여 새로운 데이터가 들어 왔을때 좋은 성능을 내는 것입니다. 이것을 일반화 성능이라고 합니다.
- 과적합은 모델의 일반화 성능을 저하시키기 때문에, 모델의 신뢰성을 떨어뜨리게 됩니다. 이로 인해 모델이 실제 문제를 해결하는 데 어려움을 겪게 되며, 비용 증가와 시간 낭비를 초래할 수 있습니다.
- 실제로 모델을 사용하는 상황에서는 학습 데이터에 포함되지 않은 데이터가 등장하며, 이를 잘 예측하는 것이 중요합니다. 따라서 과적합을 방지하여 모델의 일반화 성능을 높이는 것이 필요합니다.
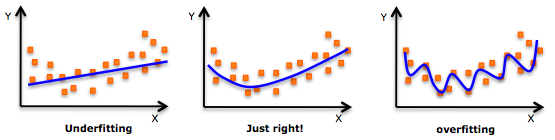
- 이러한 이유로 과적합을 피하는 것은 중요한 반면에, 아래 그림의 왼쪽처럼 언더피팅(Underfitting)은 모델이 학습 데이터에 대해서도 성능이 낮은 경우를 말합니다. 이 또한, 성능 저하를 발생 시키기 때문에 아래 그림의 가운데 처럼 적절한 적합을 찾는 것이 중요합니다.
3. 과적합이 발생하는 원인
- 학습 데이터의 양이 적거나, 클래스간 데이터가 불균형한 경우
- 예: 얼굴 인식을 위한 모델을 만들 때, 얼굴 이미지 데이터가 부족하거나 특정 인물의 이미지 데이터가 많아서 클래스간 데이터가 불균형한 경우가 있을 수 있습니다. 이 경우, 모델은 데이터가 많은 클래스에 더 많은 가중치를 주어서 그 클래스에 대해서만 잘 인식하게 됩니다. 따라서, 클래스간 데이터가 균형있게 분포되도록 데이터를 수집하거나, 데이터 증강 기법을 사용하여 학습 데이터를 늘리는 것이 도움이 됩니다.
- 학습 데이터와 실제 데이터 간의 분포가 다른 경우
- 예: 온라인 쇼핑몰에서 상품 추천 시스템을 개발한다고 가정해봅시다. 학습 데이터는 겨울 시즌 동안 수집된 데이터이고, 실제 데이터는 여름 시즌 동안 수집된 데이터입니다. 이 경우, 학습 데이터와 실제 데이터 간의 분포가 다르기 때문에, 모델이 겨울 시즌의 패턴에 과적합되어 여름 시즌의 상품 추천 성능이 저하될 수 있습니다.
- 모델의 복잡도가 높은 경우 (예: 딥러닝 모델이 너무 많은 레이어(층)나 뉴런을 가진 신경망)
- 예: 손글씨 숫자 인식 시스템을 개발한다고 가정해봅시다. 간단한 문제임에도 불구하고, 딥러닝 모델에 수십 개의 레이어와 수천 개의 뉴런을 사용한다면, 모델의 복잡도가 높아집니다. 이렇게 복잡한 모델은 학습 데이터에 지나치게 적응하여, 새로운 데이터에 대한 예측 성능이 저하되는 과적합 현상이 발생할 수 있습니다.
4. 과적합 해결 방법
- 과적합을 해결하기 위해서는 다음과 같은 방법을 사용할 수 있습니다.
- 더 많은 데이터 수집: 학습 데이터의 양을 늘려서 모델이 보다 일반화된 학습을 할 수 있도록 합니다.
- 데이터 증강: 학습 데이터를 변형시켜 데이터 양을 늘리는 방법입니다. 이미지 데이터에 대해 많이 사용합니다.
- 모델의 복잡도 감소: 모델의 복잡도를 줄여서 일반화 성능을 높일 수 있습니다. 예를 들어, 딥러닝에서는 레이어 수나 뉴런의 수를 줄여서 모델의 복잡도를 감소시킬 수 있습니다.
- 정규화: 가중치 규제나 드롭아웃과 같은 정규화 기법을 사용하여 모델의 일반화 성능을 높일 수 있습니다.
- 교차 검증: 학습 데이터를 여러 개의 부분집합으로 나누어 교차 검증을 수행하여 모델의 일반화 성능을 측정하고, 과적합을 방지할 수 있습니다.
- 조기 종료: 학습 과정에서 검증 데이터의 오차가 증가하는 지점에서 학습을 종료하여 과적합을 방지할 수 있습니다.
- 이러한 방법들을 사용하여 과적합을 방지하고 모델의 일반화 성능을 향상시킬 수 있습니다.
728x90
반응형
'인공지능 (AI)' 카테고리의 다른 글
| 객체검출 평가지표 AP(Average Precision)란? mAP, AP50, AP50:95, IoU 쉬운설명 (0) | 2023.05.04 |
|---|---|
| 분류(Classification) 성능 평가지표, 정확도, Precision, Recall, F1-score 쉬운 설명 (0) | 2023.05.01 |
| 강화학습이란? 강화학습 (Reinforcement Learning) 쉬운 설명 (0) | 2023.04.28 |
| 지도학습 비지도학습 반지도학습 자가지도학습 이란 쉬운 설명 (0) | 2023.04.27 |
| Few shot 러닝이란 One shot 러닝이란 Zero shot 러닝이란 쉬운 설명 (0) | 2023.04.27 |




댓글